Failure detection & Recovery
Failure Detection and Recovery
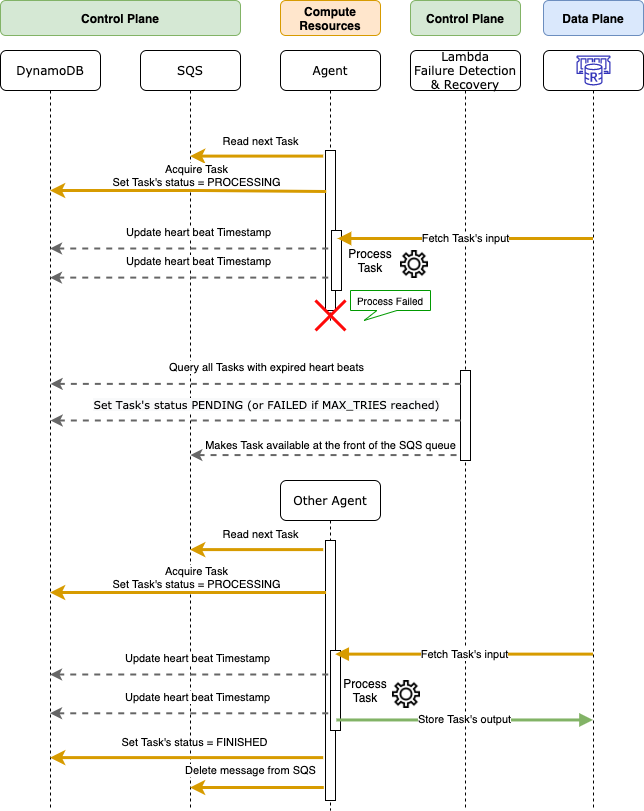
Engines acquire tasks by pulling SQS queues, respecting the rank of priority. Once a task has been received by an Engine, the Engine performs an atomic write transaction in DynamoDB to change the status of the task from “pending” to “processing”. At this stage a task is associated with that Engine.
Failure detection in HTC-Grid is implemented via heart beat mechanism. While the task is being processed, the Engine periodically emits heart-beat messages that update the row corresponding to the task in DynamoDB. These periodic updates indicate to the Control Plane that the Engine is alive and still processing the task.
Failure recovery and state reconciliation is implemented using a scheduled Lambda function. This lambda function regularly queries DynamoDB for tasks that are in the processing state but did not receive heart beats from the associated Engines for too long. This indicates that the associated Engines have failed.
Depending on the job definition, failed tasks can be retried up to a fixed number of times (by being re-inserted into the queue) or permanently moved into a ‘failed’ SQS queue for later analysis, following a dead letter queue (https://en.wikipedia.org/wiki/Dead_letter_queue) pattern. All failure events are reported.
When the task is completed, the Engine updates DynamoDB for the last time and sets task status to “completed”. Afterwards, the Engine tries to acquire a next task from an SQS queue.